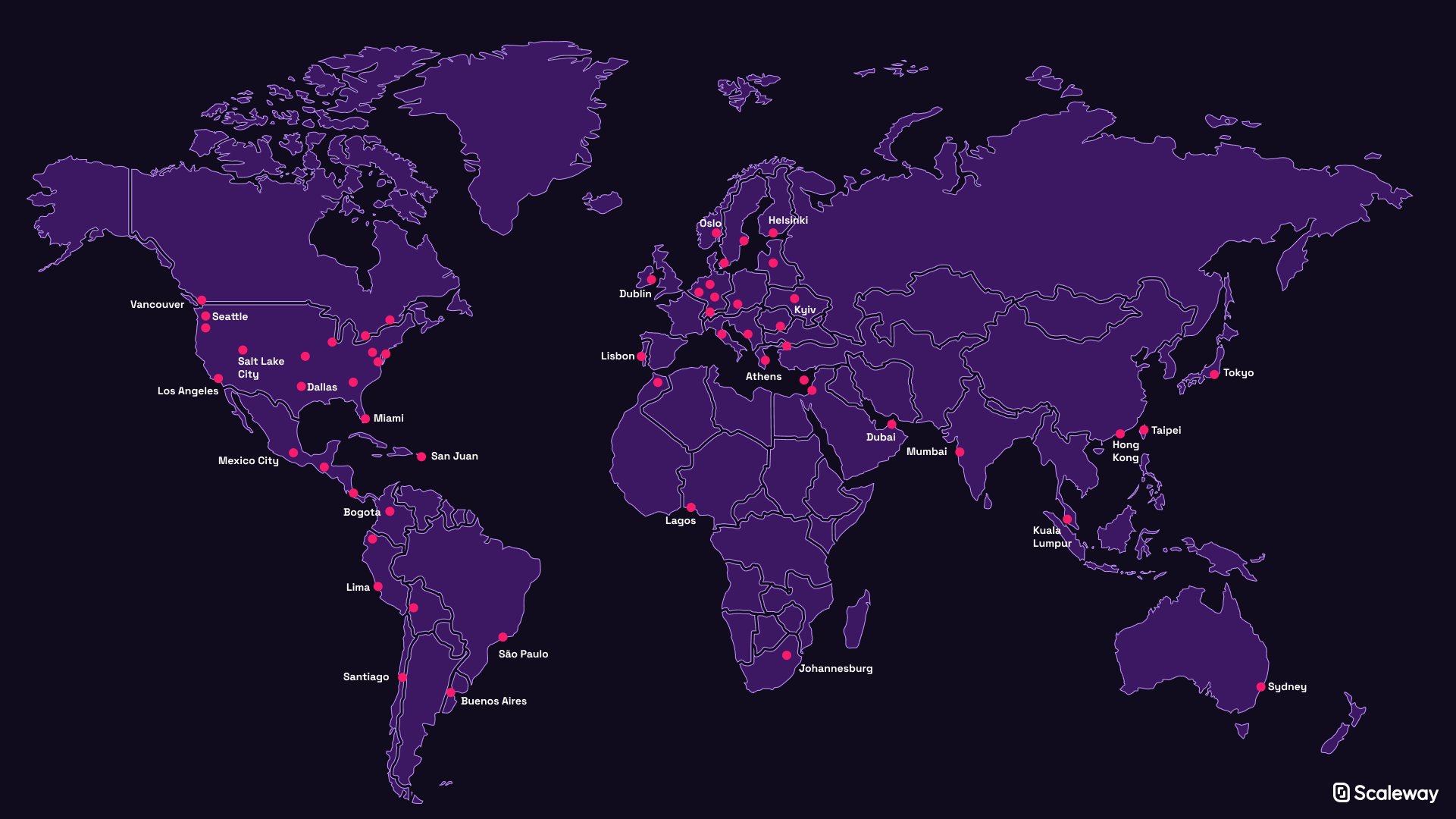
Исследование OpenAI в 2018 году показало, что объем вычислительной мощности, необходимой для обучения современных моделей искусственного интеллекта, удваивается каждые 3,4 месяца. Такой экспоненциальный рост привел к поразительному увеличению в 300000 раз всего за 6 лет — начиная с 2012 года, года, широко известного как начало эры глубокого обучения ИИ. Это явление напрямую связано с растущей сложностью лежащих в основе моделей глубокого обучения: так называемых искусственных нейронных сетей (ИНС). Вдохновленные тем, как работает наш собственный мозг, с математической точки зрения ИНС представляют собой матрицы числовых значений, называемых весами или параметрами ИНС. Подходящие параметры вычисляются на этапе разработки, требующем большого объема вычислений, который называется обучением модели, а затем используются для умножения любых входных данных, поступающих в ИНС, с целью получения (надеюсь, разумных) выходных данных. Несколько упрощенное практическое правило: чем больше количество параметров, тем мощнее модель. AlexNet, нейронная сеть, положившая начало революции глубокого обучения в 2012 году, использовала 61 миллион параметров для классификации изображений в один из 1000 классов. Если 61 миллион — это много, подождите, пока вы не услышите, сколько их в крупнейшей нейронной сети, обученной на сегодняшний день: 175 миллиардов! Это количество значений, параметризующих GPT-3 (Generative Pre-Trained Transformer 3), разработанный OpenAI в 2020 году. Получив приглашение, GPT-3 может генерировать работающий код, писать стихи и создавать текст, который почти невозможно определить кроме того, что исходит от человека. Этот впечатляющий подвиг машинного обучения еще несколько лет назад можно было бы считать чистой научной фантастикой, поэтому есть большие надежды на то, что может предложить следующий по величине ИИ.
Однако за такие новаторские достижения приходится платить. Фактически, затраты, связанные с вычислительными ресурсами, необходимыми для обучения этих моделей, двукратны. Начнем с очевидного: денежных затрат, которые оплачивают исследовательские группы и компании, стоящие за созданием моделей. Однако это еще не все. Ущерб, который обучение модели наносит окружающей среде, — это вторая цена, которую несем все мы. К счастью, нам не нужно позволять этим соображениям откладывать подъем машин, если мы мудро выбираем место обучения. Недавнее исследование, проведенное Google, показывает, что определенный выбор, сделанный в отношении того, как и где мы обучаем нейронные сети, может снизить связанный с этим углеродный след до 1000 раз!
Давайте возьмем пример GPT-3 и посмотрим, сколько энергии можно сэкономить, проведя обучение в энергоэффективном центре обработки данных по сравнению с традиционным. GPT-3 был обучен на кластере, состоящем из 10000 графических процессоров V100 Nvidia: аппаратных ускорителей, разработанных с единственной целью оптимизации вычислений, используемых при обучении искусственных нейронных сетей. Потребляемая мощность одного графического процессора V100 составляет 300 Вт. Сколько времени нужно было на обучение GPT-3? Согласно исходной статье, для окончательного обучения модели требовалось 3,14x1023 FLOPS (операций с плавающей запятой в секунду). Общая стоимость обучения, вероятно, будет на порядок выше, поскольку типичный проект глубокого обучения включает обучение множеству различных вариантов модели, прежде чем выбрать наиболее эффективную. Для минимальной оценки возьмем 3,14x1023 FLOPS и рассмотрим только мощность, потребляемую графическими процессорами (в то время как на самом деле нам пришлось бы добавить в смесь процессоры, сеть и память). С точки зрения производительности V100 может обрабатывать 14 терафлопс при использовании чисел с плавающей запятой одинарной точности, но теоретически это число удваивается до 28 терафлопс для формата половинной точности, который использовался OpenAI. При использовании 10 000 графических процессоров это соответствует примерно 13 дням обучения или 10 000 x (300 Вт) x (13 дней) = 936 МВт-ч энергии, потребляемой только графическими процессорами.
Любой, кто по неосторожности положил ноутбук себе на колени и запустил сразу слишком много приложений, знает, что во время работы машины нагреваются. 10000 графических процессоров, которые работают на пределе своих возможностей в течение двух недель подряд, сильно нагреваются. Фактически, большая часть энергии, потребляемой в типичном центре обработки данных, идет не только на включение серверов, но и на охлаждение самого центра обработки данных. Эти и другие сопутствующие расходы учитываются показателем, называемым PUE, Power Usage Effectiveness. Этот коэффициент представляет собой отношение A / B, которое измеряет общее количество энергии A, необходимое для передачи конечного количества энергии B серверу. PUE всегда больше 1, так как значение 1 будет означать идеальную эффективность, когда на обслуживание центра обработки данных не тратится энергия. В традиционном центре обработки данных PUE может быть где-то около 1,5 и более. Это означает, что фактические затраты энергии на обучение такой модели, как GPT-3, составят не менее 936 МВтч x 1,5 = 1404 МВтч. Есть ли способ уменьшить это число?
Самый простой способ сократить количество энергии, затрачиваемой на облачные вычисления, — это выбрать центр обработки данных с более низким PUE. У Scaleway DC5, расположенного в пригороде Парижа, PUE составляет 1,15, что означает сокращение накладных расходов с 50% до 15%. Эти сокращения распространяются как на создателей модели, так и на среду, от которой мы все получаем прибыль. Вернемся к примеру с GPT-3: обучение в центре обработки данных, таком как DC5, приведет к энергопотреблению 936 МВтч x 1,15 = 1076 МВтч, сэкономив 328 МВтч, или 23% энергии, потребляемой традиционным центром обработки данных.. Для сравнения: для питания 2000 домов во Франции требуется около 1 МВт. Однако, хотя этот расчет учитывал только обучение окончательной модели, в действительности эксперименты, необходимые для достижения этой точки, увеличили бы общую стоимость энергии в 10-100 раз. Другими словами, обучение такой модели, как GPT-3, в энергоэффективном центре обработки данных, таком как DC5, позволяет сэкономить достаточно энергии, чтобы управлять средним городом в течение нескольких дней, а возможно, и недель.
При том, что размер современных искусственных нейронных сетей увеличивается, разница между обучением следующего по величине ИИ в энергоэффективном и традиционном центре обработки данных вполне может стать источником энергии для небольшой, но живописной европейской столицы. на месяц. Пища для мысли (человеческой и синтетической)!